B-frame
YUV
Introduction
The introduction section is fetched from this GitHub page. Copyright Jim-Bar.webarchive
First of all: YUV pixel formats and Recommended 8-Bit YUV Formats for Video Rendering. Chromium’s source code contains good documentation about those formats too: chromium/src/media/base/video_types.h and chromium/src/media/base/video_frame.cc (search for RequiresEvenSizeAllocation(), NumPlanes() and those kinds of functions).
YUV?
You can think of an image as a superposition of several planes (or layers in a more natural language). YUV formats have three planes: Y, U, and V.
Y is the luma plane, and can be seen as the image as grayscale. U and V are referred to as the chroma planes, which are basically the colours. All the YUV formats have these three planes, and differ by the different orderings of them.
Sometimes the term YCrCb is used. It’s essentially the same thing: Y, Cr, Cb respectively refer to Y, U, V although Cr and Cb are sometimes used when speaking of the components of U and V (that is U = Cr1Cr2…Crn and V = Cb1Cb2…Cbn).
420, 422, (…), And Subsampling
The chroma planes (U and V) are subsampled. This means there is less information in the chroma planes than in the luma plane. This is because the human eye is less sensitive to colours than luminance; so we can just gain space by keeping less information about colours (chroma planes) than luminance (luma plane, Y).
The subsampling is expressed as a three part ratio: J:a:b (e.g. 4:2:0). This ratio makes possible to get the size of the planes relative to each others. Refer to the Wikipedia article “Chroma subsampling” for more information.
Basically the chroma planes are often shorter than the luma plane. Most commonly, the ratio is length(Y) / n = length(U) = length(V) where n is 1, 2, 4, …
Packed, Planar, and Semi-planar
YUV formats are either:
- Packed (or interleaved)
- Planar (the names of those formats often end with “p”)
- Semi-planar (the names of those formats often end with “sp”)
Those terms define how the planes are ordered in the format. In the memory:
- Packed means the components of
Y,U, andVare interleaved. For instance: Y1U1Y2V1Y3U2Y4V2…Yn-1Un/2YnVn/2. - Planar means the components of
Y,U, andVare respectively grouped together. For instance: Y1Y2…YnU1U2…Un/2V1V2…Vn/2. - Semi-planar means the components of
Yare grouped together, and the components ofUandVare interleaved. For instance: Y1Y2…YnU1V1U2V2…Un/2Vn/2
Semi-planar formats are sometimes put in the Planar family.
Some YUV Formats
The following formats are described in the picture:
- YV12
- I420 = IYUV = YUV420p (sometimes YUV420p can refer to YV12)
- NV21
- NV12 = YUV420sp (sometimes YUV420sp can refer to NV21)
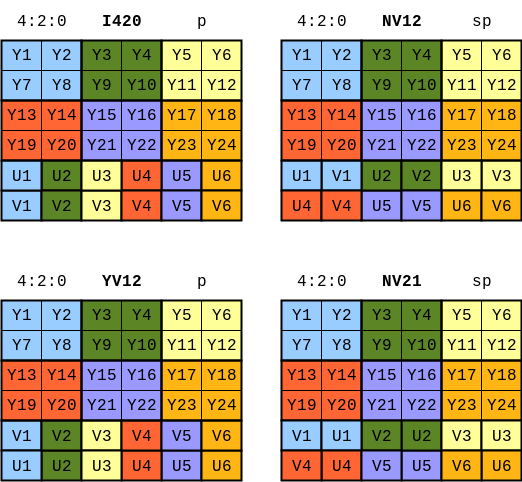
NV12
FFMPEG with NVDEC
Code for extracting raw YUV data from AVFrame:
uint8_t *y = new_frame, *u = y + height * width, *v = u + height / 2 * width / 2;
// Y-plane
for (int i = 0; i < height; i++) {
memcpy(y + i * width, frame->data[0] + i * linesize_y, width);
}
// U-plane
for (int i = 0; i < height / 2; i++) {
for (int j = 0; j < width; j += 2) {
u[i * width / 2 + j / 2] = frame->data[1][i * linesize_uv + j];
}
}
// V-plane
for (int i = 0; i < height / 2; i++) {
for (int j = 1; j < width; j += 2) {
v[i * width / 2 + (j - 1) / 2] = frame->data[1][i * linesize_uv + j];
}
}I420
FFMPEG with CPU decoder
- When using default CPU decoder, the decoded
AVFramestores data in I420 format
frame->data[0]stores Y-planeframe->data[1]stores U-planeframe->data[2]stores V-planeframe->linesize[0] == width,frame->linesize[1] == frame->linesize[2] == width / 2
Code for extracting raw YUV data from AVFrame:
uint8_t *y = new_frame, *u = y + height * width, *v = u + height / 2 * width / 2;
// Y-plane
for (int i = 0; i < height; i++) {
memcpy(y + i * width, frame->data[0] + i * linesize_y, width);
}
// U-plane
for (int i = 0; i < height / 2; i++) {
memcpy(u + i * width / 2, frame->data[1] + i * linesize_uv, width / 2);
}
// V-plane
for (int i = 0; i < height / 2; i++) {
memcpy(v + i * width / 2, frame->data[2] + i * linesize_uv, width / 2);
}RGB
Convert YUV to RGB
CUDA implementation to convert buffer from YUV format to RGB format:
__global__ void k_yuv_to_rgb(const uint8_t *yuv_buf, uint8_t *rgb_buf, int width, int height) {
unsigned coord_x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned coord_y = blockIdx.y * blockDim.y + threadIdx.y;
if (coord_x >= width || coord_y >= height) return;
unsigned frame_idx = blockIdx.z;
unsigned local_idx = coord_y * width + coord_x;
unsigned yuv_offset = frame_idx * yuv_fsize(width, height);
unsigned rgb_offset = frame_idx * rgb_fsize(width, height);
unsigned uv_index = (coord_y / 2) * (width / 2) + (coord_x / 2);
const uint8_t *y_plane = yuv_buf + yuv_offset;
const uint8_t *u_plane = yuv_buf + yuv_offset + (width * height);
const uint8_t *v_plane = yuv_buf + yuv_offset + (width * height) + ((width / 2) * (height / 2));
int y = y_plane[local_idx];
int u = u_plane[uv_index];
int v = v_plane[uv_index];
int c = y - 16;
int d = u - 128;
int e = v - 128;
int r = min(max((298 * c + 409 * e + 128) >> 8, 0), 255);
int g = min(max((298 * c - 100 * d - 208 * e + 128) >> 8, 0), 255);
int b = min(max((298 * c + 516 * d + 128) >> 8, 0), 255);
rgb_buf[rgb_offset + 3 * local_idx] = r;
rgb_buf[rgb_offset + 3 * local_idx + 1] = g;
rgb_buf[rgb_offset + 3 * local_idx + 2] = b;
}
__host__ void yuv_to_rgb(const uint8_t *d_yuv_buf, uint8_t *d_rgb_buf, int width, int height, int num_frames) {
dim3 blk(16, 16, 1);
dim3 grd((width + blk.x - 1) / blk.x,
(height + blk.y - 1) / blk.y,
num_frames);
k_yuv_to_rgb<<<grd, blk>>>(d_yuv_buf, d_rgb_buf, width, height);
}